Fast algorithm for document image restoration
FAIR ?
FAIR est l'acronyme pour "Fast Algorithm for document Image Restoration" qui veut grosso-modo dire que c'est une méthode de binarisation rapide.
Binarisation ?
Il existe deux manières d'appréhender l'indexation. Certaines bibliothèques numériques ont fait le choix d'indexer manuellement leurs images alors que d'autres ont fait le pari de se lancer dans des solutions incluant de l'indexation automatique. Dans le premier cas, de nombreux défauts comme la lourdeur de la tâche ou encore la subjectivité des mots-clefs choisis pour indexer les documents rendent difficile sa mise en oeuvre. Mais la deuxième approche, bien que résolvant les deux précédents problèmes, n'est pas plus simple à mettre en place. En effet, les documents sont parfois en mauvais état, mal numérisés et/ou dans un alphabet ne permettant pas de retrouver facilement le texte dans les images.
Parallèlement à cette indexation de documents des bibliothèques, une autre difficulté se rapprochant de cette problématique a été soulevé par les bases de données multimédias. Les sites comme YouTube où tout le monde peut déposer une vidéo, ou encore les bases de données d'images, sont des sources intarissables de documents multimédias qu'il est parfois difficile d'indexer. Une bonne manière d'ajouter de l'information sémantique (par opposition à l'information bas niveau, comme une couleur, une texture...) est d'utiliser le texte présent dans l'image. Il est alors possible d'obtenir le nom du présentateur, la ville, le sujet...
Binarisons !
L'objectif de la binarisation est donc de retrouver les pixels de texte, et de séparer en deux classes le document : texte et fond. Hélas, bien souvent les documents présentent un aspect fortement dégradé, avec un fond non uniforme, des pages déchirées, froissés et/ou des tâches d'encre recouvrant partiellement le texte. Cela rend donc assez difficile cette tâche !
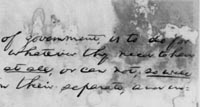


Notre approche
Pour retrouver la position du texte, généralement on se base sur une analyse statistique locale de l'image. C'est à dire qu'on calcule la couleur moyenne (et d'autres stats comme la variance) à un endroit de l'image et on va chercher à savoir si le pixel central est plutôt du texte ou du fond.
L'idée que nous avons suivie est plutôt de se dire que le fond et le texte ont deux couleurs différentes, et on va chercher à estimer ces valeurs.
Pour les détails théorique, je vous encourage à lire la description qui a été publié en 2013 :
Lelore-Bouchara : FAIR: a fast algorithm for image restoration
Pour les détails pratiques, n'hésitez pas à tester notre binarisation!
| Phenix told: at 2014-02-11 23:53:34 |
Admin, je vous remercie de votre réponse et je vous solliciterai par Email dans moins d'un moi. Cdt. |
|---|---|
| Admin told: at 2014-02-11 22:36:34 |
Bonjour, nous avons déposé un brevet sur cet algo donc nous ne pouvons vous fournir une API. Par contre, suivant l'usage nous pouvons nous arranger. N'hésitez pas à me contacter via gmail @thibault.lelore! |
| Phenix told: at 2014-02-11 22:05:02 |
Bonjour, Pour-j avoir une API me permettant d'utiliser automatiquement votre Algo de binarization sur mes propres images ?! |
| Admin told: at 2013-12-09 14:46:08 |
Voila, le lien est réparé ;) |
| dami told: at 2013-12-09 13:17:05 |
bonjour le lien est invalide ... est-il possible d'en avoir un autre merci bien |
| Post a question: |




